
This is my reading notes for Chapter 4 in book “System Design Interview – An insider’s guide (Vol. 1)”.
Table of Contents
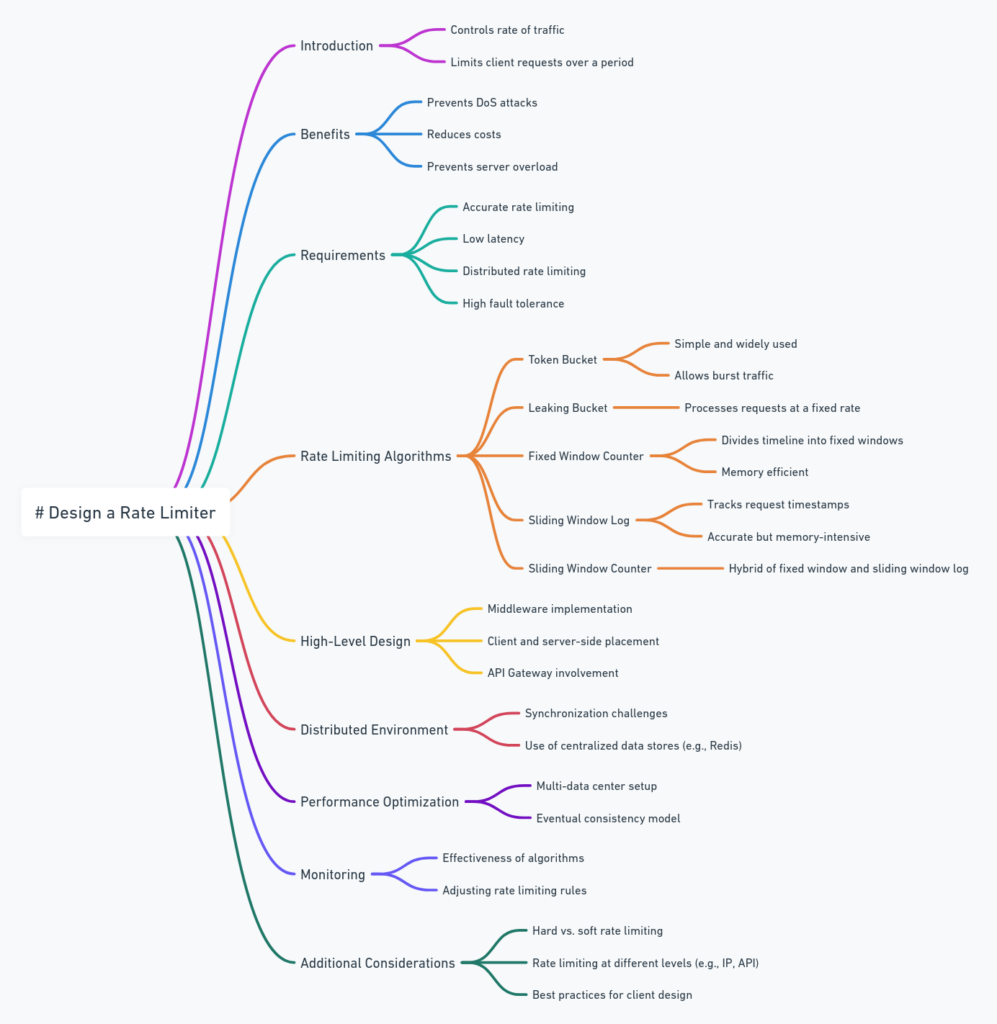
A rate limiter controls the rate of traffic sent by a client or service, typically in an HTTP environment. It limits the number of client requests over a specific period and blocks requests exceeding this limit. Rate limiting is crucial for:
- Preventing Denial of Service (DoS) attacks: It helps prevent intentional or unintentional resource exhaustion by limiting the number of requests a client can make.
- Reducing costs: By limiting API requests, particularly when using paid third-party APIs, companies can reduce costs.
- Preventing server overload: It ensures that servers are not overwhelmed by excessive requests, particularly from bots or misbehaving clients.
Key Design Requirements
The rate limiter must:
- Accurately limit excessive requests based on specific rules (e.g., per IP address or user ID).
- Maintain low latency so it does not slow down HTTP response times.
- Be memory efficient to handle large-scale environments.
- Support distributed rate limiting across multiple servers or processes.
- Handle exceptions gracefully, providing clear feedback to clients when they are throttled.
- Be highly fault-tolerant, ensuring that system issues do not lead to widespread failures.
Placement of the Rate Limiter
- Client-Side Implementation: Generally unreliable because clients can be manipulated. It also offers less control over the rate limiting process.
- Server-Side Implementation: More reliable and commonly used. It can be integrated directly into the API server or implemented as a middleware component.
- Middleware in API Gateway: In cloud microservices, rate limiting is often implemented within an API gateway, which can manage other tasks like SSL termination and authentication as well.
Algorithms for Rate Limiting
1. Token Bucket Algorithm
- How It Works:
- A “bucket” has a predefined capacity and tokens are added to it at a set rate.
- Each request consumes one token. If there are no tokens left, the request is dropped.
- Pros:
- Supports Bursts: Allows a burst of traffic as long as there are enough tokens in the bucket.
- Simple and Memory Efficient: Easy to implement and doesn’t require extensive memory usage.
- Cons:
- Complex Tuning: Finding the right bucket size and refill rate can be challenging, particularly for varying traffic patterns.
2. Leaking Bucket Algorithm
- How It Works:
- Similar to the token bucket but processes requests at a fixed rate using a FIFO queue.
- If the queue is full, incoming requests are dropped.
- Pros:
- Stable Outflow Rate: Ideal for scenarios requiring consistent processing rates.
- Memory Efficient: Only stores a limited number of requests in the queue.
- Cons:
- Vulnerable to Bursts: A sudden influx of requests can fill the queue with older requests, causing more recent ones to be dropped.
- Complex Tuning: Like the token bucket, it can be difficult to tune correctly.
3. Fixed Window Counter Algorithm
- How It Works:
- Divides time into fixed windows (e.g., 1 second, 1 minute) and counts the requests in each window.
- If the count exceeds a predefined threshold, additional requests within that window are dropped.
- Pros:
- Easy to Implement: Simple to understand and implement.
- Memory Efficient: Requires minimal memory to maintain counters for each window.
- Cons:
- Edge Case Vulnerability: Requests at the boundary of two time windows can exceed the rate limit because the count resets with each new window.
4. Sliding Window Log Algorithm
- How It Works:
- Keeps a log of request timestamps and only retains those within the current time window.
- Requests are allowed or denied based on the count of recent requests in the log.
- Pros:
- Accurate Rate Limiting: Provides precise control over the number of requests in any rolling time window.
- Cons:
- Memory Intensive: Requires storing timestamps for all requests, which can consume a lot of memory.
5. Sliding Window Counter Algorithm
- How It Works:
- Combines elements of both fixed window counters and sliding window logs.
- Counts requests in the current window and uses a weighted average to include a fraction of the requests from the previous window.
- Pros:
- Smooths Traffic Spikes: Mitigates the risk of sudden traffic spikes by averaging counts across windows.
- Memory Efficient: Uses less memory compared to sliding window logs.
- Cons:
- Approximation: The method is not entirely accurate since it assumes an even distribution of requests, which might not always be the case.
High-Level Architecture
- Counter Storage: Counters are typically stored in an in-memory cache like Redis, which supports fast access and time-based expiration.
- Workflow:
- A request is sent to the rate limiter.
- The rate limiter checks the counter in the cache to see if the limit has been reached.
- If the limit is reached, the request is rejected. Otherwise, the counter is incremented, and the request is forwarded to the API server.
Detailed Design Considerations
- Rate Limiting Rules: Stored in configuration files and define the limits based on various factors like user ID, IP address, or specific API endpoints.
- Handling Throttled Requests: Throttled requests return an HTTP
429 Too Many Requestsstatus code with headers indicating when the client can retry. - Distributed Environment: Handling race conditions and synchronization issues is challenging in distributed systems. Using centralized storage like Redis helps maintain consistency across multiple servers.
Conclusion
Designing a rate limiter requires a balance between accuracy, performance, and fault tolerance. By carefully selecting and implementing the appropriate algorithm, you can ensure that the system effectively manages request rates, protects resources, and provides a responsive user experience.