This is my reading notes for Chapter 13 in book “System Design Interview – An insider’s guide (Vol. 1)”.
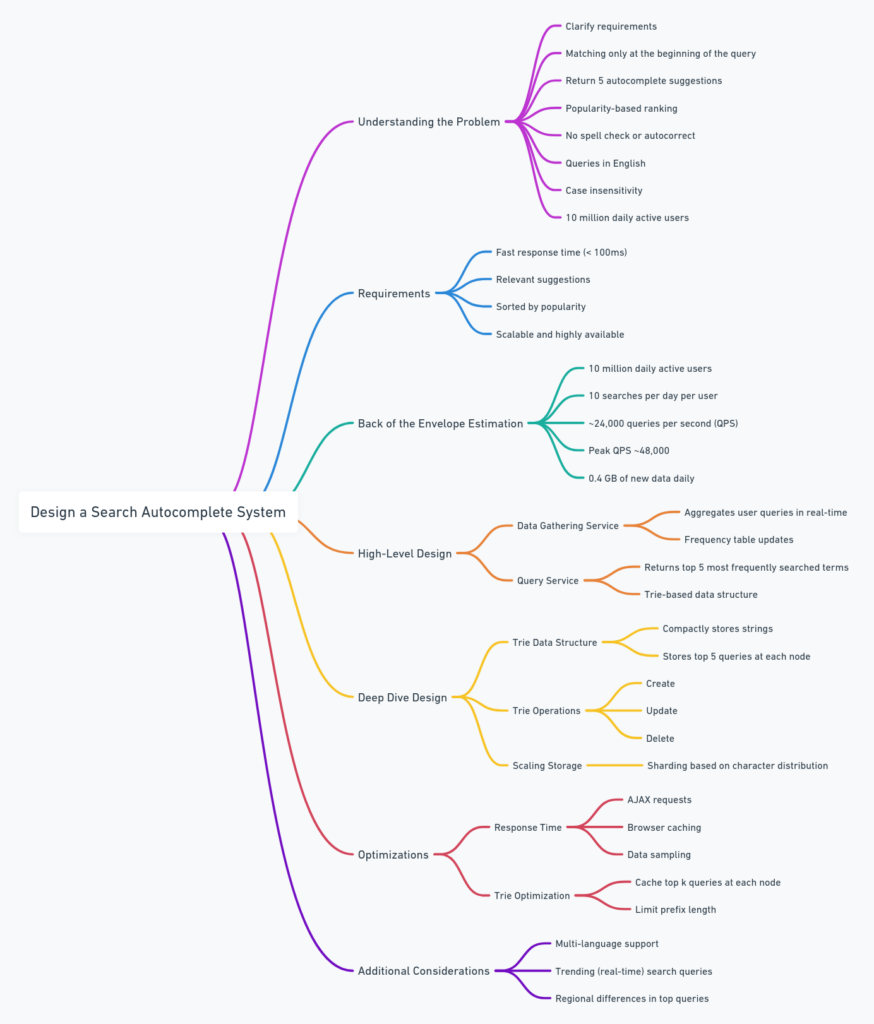
Chapter Overview: This chapter focuses on designing a search autocomplete system—a critical feature used in search engines, e-commerce platforms, and other applications to enhance user experience by suggesting relevant search terms as the user types. The chapter guides readers through defining requirements, performing estimations, designing a high-level architecture, and diving into detailed implementation considerations.
Key Requirements:
- Fast Response Time:
- Goal: The system should provide autocomplete suggestions within 100 milliseconds to ensure a smooth and responsive user experience.
- Explanation: If the system takes too long, it disrupts the user’s flow and may lead to frustration. For high traffic systems, every millisecond counts, so optimization is critical.
- Example: When a user types “how to cook” into a search bar, they should instantly see suggestions like “how to cook rice” or “how to cook pasta.”
- Relevance:
- Goal: The suggestions must be relevant to what the user is likely to search for, based on the prefix they have typed.
- Explanation: Relevance is often determined by analyzing historical search data, user behavior, and trends. The system must be able to rank these suggestions effectively.
- Example: For the prefix “pyt,” relevant suggestions might include “python,” “python tutorial,” and “python string methods” if the system has detected a trend in users searching for Python-related terms.
- Sorted Results:
- Goal: Suggestions should be sorted based on criteria such as popularity, recency, or a combination of factors.
- Explanation: Sorting helps users find the most commonly sought-after information first, reducing the time they spend searching.
- Example: For the prefix “star,” the system might prioritize “Starbucks” over “Starfish” if “Starbucks” is more frequently searched.
- Scalability:
- Goal: The system should be able to handle millions of users, particularly during peak times, without degradation in performance.
- Explanation: As user bases grow, the system must be able to scale horizontally (by adding more servers) or vertically (by upgrading hardware) to manage the load.
- Example: An e-commerce site like Amazon must ensure that its autocomplete system can handle spikes in traffic during events like Black Friday.
- High Availability:
- Goal: The system should remain operational even if parts of it fail.
- Explanation: High availability is achieved through redundancy and failover mechanisms. If one server or data center goes down, others should seamlessly take over.
- Example: If a server handling autocomplete requests crashes, another server should immediately start handling those requests without users noticing any disruption.
Back-of-the-Envelope Estimation:
- Assumptions:
- 10 million daily active users (DAU).
- Each user performs around 10 searches per day.
- Each search generates approximately 20 autocomplete requests (e.g., for the query “apple,” requests would include “a,” “ap,” “app,” etc.).
- Storage requirement: Each query might require about 20 bytes (including metadata).
- Calculation:
- Queries per Second (QPS):
- Total queries = 10 million users * 10 searches/day * 20 requests per search = 2 billion requests/day.
- QPS = 2 billion requests/day / 86,400 seconds/day ≈ 23,000 QPS.
- Peak QPS: The peak load might be double during busy times, leading to around 46,000 QPS.
- Queries per Second (QPS):
- Storage Needs:
- Assuming 20 bytes per query, daily storage = 2 billion * 20 bytes = 40 GB/day.
- If queries are stored for a year, total storage ≈ 40 GB/day * 365 ≈ 14.6 TB/year.
High-Level Design:
- Data Gathering Service:
- Purpose: This service collects user queries in real-time and updates the frequency of each query in a data store.
- Components: A database (like a distributed NoSQL store) that tracks how often each query is made, and a processing service that aggregates this data.
- Example: When multiple users search for “new york times,” the system increments the frequency count for this phrase in the database.
- Query Service:
- Purpose: The query service quickly retrieves the top suggestions for the user as they type.
- Components: A trie (prefix tree) that stores query prefixes, with nodes containing references to the top queries starting with that prefix.
- Example: When a user types “mo,” the service might return “movies,” “mortgage rates,” and “motorcycles” as the top suggestions.
- Ranking and Sorting:
- Purpose: To sort the suggestions based on predefined criteria like popularity, recency, or personalization.
- Components: Ranking algorithms that consider query frequency, user behavior, and trends.
- Example: If “mortgage rates” is currently trending, it might appear higher in the suggestions for “mo” compared to “movies.”
- Sharding and Replication:
- Purpose: To ensure the system can scale and handle high traffic, the data is sharded (distributed) across multiple servers.
- Components: A distributed database that shards data based on the prefix (e.g., the first letter or first two letters of the query).
- Example: Queries starting with “a” might be stored on one server, while those starting with “b” are on another. This prevents any one server from being overwhelmed.
Design Deep Dive:
- Trie Data Structure:
- Purpose: The trie is used to efficiently store and retrieve query prefixes. It supports fast lookup times, which are crucial for meeting the 100 ms response time.
- Optimization: Each node in the trie not only stores the current character but also maintains a list of top search queries that share that prefix.
- Example: For the prefix “ap,” the trie node might store references to “apple,” “apartment,” and “application,” ranked by their popularity.
- Real-Time Data Update:
- Purpose: To keep the trie updated with the latest search trends without causing latency issues.
- Strategy: Instead of updating the trie for every single search in real-time, the system batches updates and processes them at regular intervals (e.g., hourly or daily).
- Example: If there’s a sudden surge in searches for “apocalypse,” the trie might be updated at the end of the day to include this in the top suggestions for “ap.”
- Handling Large Data Sets:
- Sharding: To manage large amounts of data, the trie is split across multiple servers. Initially, sharding might be based on the first character of the query, but this can lead to imbalances.
- Advanced Sharding: Analyze historical query data to distribute load more evenly. For instance, “s” might be broken down further into “sa,” “sb,” etc., to prevent any single shard from becoming too large.
- Example: If “s” is a popular starting letter, the system might shard based on the first two letters, distributing “sa,” “sb,” and “sc” queries to different servers.
- Caching Popular Queries:
- Purpose: Caching frequently searched queries ensures faster response times by reducing the need to repeatedly query the trie.
- Strategy: Implement an in-memory cache (like Redis) to store the top N queries for each popular prefix.
- Example: For the prefix “re,” the cache might store “restaurants near me,” “red dress,” and “recipe ideas” to quickly serve these popular suggestions without accessing the trie.
Scaling the Storage:
- Problem: As the trie grows, it may no longer fit on a single server, leading to the need for distributed storage.
- Solution:
- Sharding: Start by sharding based on the first character or the first two characters. If the data is still too large, implement a more granular sharding strategy.
- Replication: Use data replication to ensure that even if one shard fails, another can take over without downtime.
- Example: Sharding by prefix (“a” on server 1, “b” on server 2, etc.) might eventually evolve to sharding by first two characters (“aa-ab” on server 1, “ac-ad” on server 2) to balance load and storage.
Optimizing the System for Real-Time Trends:
- Problem: During significant events (e.g., breaking news, viral content), the system must adapt quickly to new trends.
- Solution:
- Real-Time Data Processing: Use streaming data processing systems like Apache Kafka to detect trending queries in real-time and update the trie or cache accordingly.
- Trending Queries: Introduce a mechanism to detect and prioritize these in autocomplete suggestions dynamically.
- Example: If a new movie “Inception 2” is announced, the system should immediately start suggesting “Inception 2” as a top result after the user types “inc.”
Wrap-Up and Additional Considerations:
- Multi-Language Support:
- Problem: Supporting multiple languages can complicate the design, especially with languages that use different character sets.
- Solution: Store Unicode characters in trie nodes and ensure the system can handle different language-specific sorting and ranking rules.
- Example: For a multi-lingual site, the system might need to suggest both “sushi” and “寿司” (Japanese for sushi) depending on the user’s language preference.
- Monitoring and Analytics:
- Problem: Without proper monitoring, it’s hard to know if the system is performing optimally.
- Solution: Implement logging and analytics to track query performance, cache hit rates, and user engagement with suggestions.
- Example: Monitoring tools could alert the team if response times exceed 100 ms, prompting an investigation into potential bottlenecks.
- Error Handling and Failover:
- Problem: The system needs to be resilient to failures, such as a server going offline.
- Solution: Implement failover strategies where requests are automatically routed to a backup server if the primary one fails.
- Example: If a shard responsible for “a” queries fails, another server should immediately take over, ensuring users still receive suggestions without interruption.
The notes I took provide a comprehensive overview of the key concepts, requirements, and design strategies discussed in Chapter 13. The examples are tailored to help illustrate how the design principles apply in real-world scenarios, making it easier to grasp the complexities involved in designing a robust and scalable search autocomplete system.
I found this article so compelling and insightful!
The website is well-maintained and filled with valuable resources.
I got what you mean , appreciate it for posting.Woh I am pleased to find this website through google. “Do not be too timid and squeamish about your actions. All life is an experiment.” by Ralph Waldo Emerson.
This article is packed with great information and is very helpful.
The website is an excellent resource for learning.