

This is a summary of the Youtube video presented by Andrej Karpathy which deep dives into the LLMs and help to gain insights of the LLMs/ChatGPT.
It’s highly recommended to watch the whole video if you are a beginner and curious about LLMs.
Introduction
Large Language Models (LLMs) like ChatGPT have revolutionized natural language processing (NLP), but what exactly happens behind the scenes? Many people interact with these models daily without understanding how they function.
This video provides a technical deep dive into LLMs, covering:
- How LLMs like ChatGPT are built
- The core principles behind training and inference
- Tokenization, neural networks, and transformers
- Why massive computational resources are required
- Common challenges and limitations

By the end, you’ll have a clear understanding of how ChatGPT operates and why AI companies are investing billions into these models.
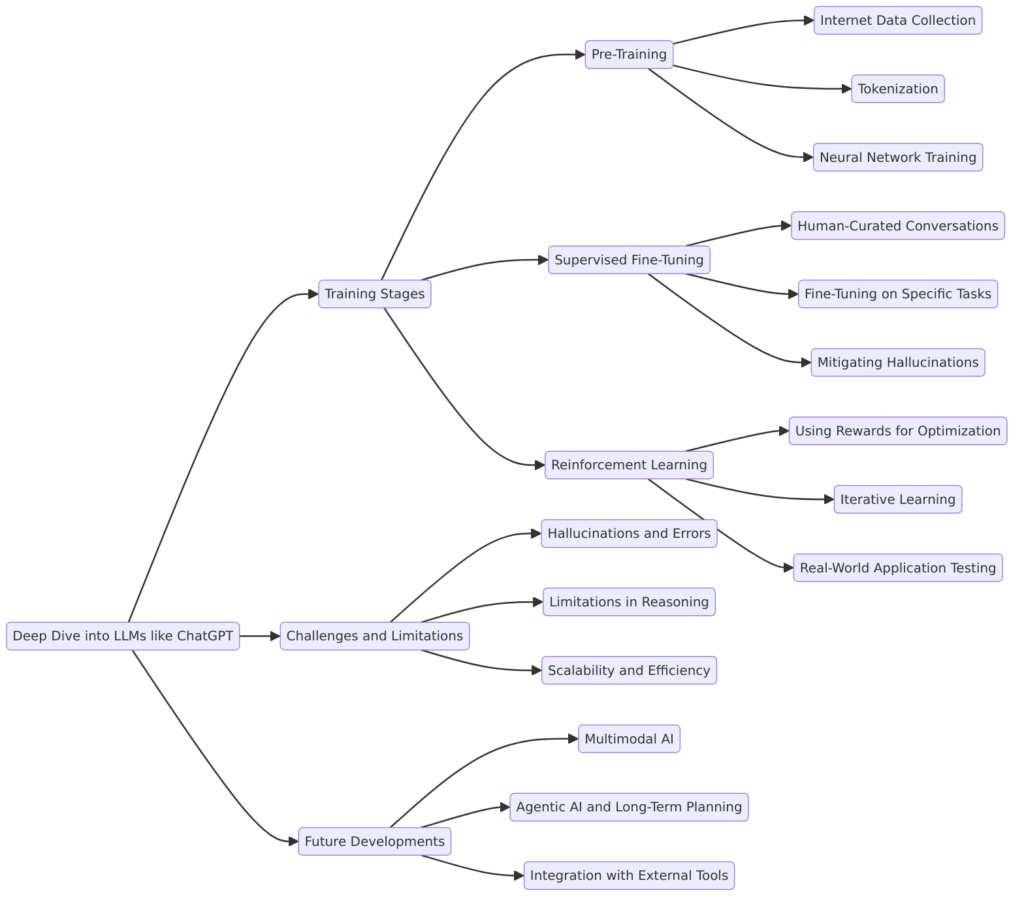
1. The Foundation: Training Data and Preprocessing
Where Does the Data Come From?
The first step in building an LLM is acquiring vast amounts of text data. The internet is a goldmine of information, and companies like OpenAI, Google, and Meta collect data from:
- Webpages: News sites, Wikipedia, blogs, forums
- Books and academic papers
- Code repositories (e.g., GitHub)
- Transcribed speech (from videos, podcasts, etc.)
A common dataset used for training is Common Crawl, which archives billions of web pages. However, this raw data is not directly used—it undergoes extensive preprocessing.
Filtering and Cleaning the Data
Not all text is useful. The preprocessing pipeline applies:
- URL filtering: Removing known spam, malware, or unreliable sources.
- Text extraction: Stripping out HTML, CSS, and JavaScript to leave only the core text.
- Language filtering: Keeping only English or other target languages.
- Deduplication: Removing duplicate content to prevent overfitting.
- Personally Identifiable Information (PII) removal: Filtering out sensitive information (e.g., phone numbers, social security numbers).
👉 Example: If a website has multiple versions of the same article with slight variations, deduplication ensures that the model doesn’t train on redundant text.
Once cleaned, the dataset is ready for the tokenization process.
2. Tokenization: Converting Text into Numerical Data
Neural networks don’t process text directly—they work with numbers. Tokenization is the process of converting text into a numerical format that the model can understand.
How Tokenization Works
Each word, subword, or character is assigned a unique token ID.
Example: Tokenizing “Hello, world!”
| Text | Tokens | Token IDs |
|---|---|---|
| “Hello” | hello | 15339 |
| “,” (comma) | , | 11 |
| “world” | world | 1917 |
| “!” (exclamation) | ! | 0 |
💡 Key Insight: LLMs use subword tokenization (Byte Pair Encoding or BPE) instead of just words. This allows them to handle rare words efficiently.
👉 Example:
- “Artificial” might be tokenized as
Artificial - “Artificially” might be split into
Artificial+ly - “Unartificially” might be split into
Un+artificial+ly
Since “Artificial” is common, the model learns its meaning faster. But for rare words, breaking them into known parts improves generalization.
Why does tokenization matter?
- The shorter the sequence, the more efficiently the model processes it.
- The number of tokens impacts inference speed and cost (LLMs process a limited number of tokens per request).
- Different models have different tokenization strategies (GPT-4 uses ~100,000 tokens, while GPT-2 used ~50,000).
3. Training the Neural Network
Training Objective: Predicting the Next Token
LLMs like GPT are trained using causal language modeling, meaning they predict the next token based on previous tokens.
Example: Predicting Text
If given the prompt:
👉 "The Eiffel Tower is located in"
The model will generate probabilities for possible next words:
| Next Token | Probability (%) |
|---|---|
"Paris" | 80% |
"France" | 15% |
"Europe" | 3% |
"New York" | 0.1% |
💡 Key Insight: The model is not retrieving a fact from a database—it’s computing the most statistically likely next word based on its training data.
The Transformer Architecture
Modern LLMs are based on Transformers, a type of deep neural network.
Key components:
- Self-Attention Mechanism: Allows the model to understand relationships between words, even across long distances.
- Positional Encoding: Since transformers process all tokens at once (instead of sequentially like RNNs), they need a way to track word order.
- Feedforward Layers: Perform nonlinear transformations to improve accuracy.
Why Transformers Are Better Than RNNs
- Parallel processing: Unlike Recurrent Neural Networks (RNNs), which process tokens one at a time, transformers handle entire sequences simultaneously.
- Better long-term memory: Self-attention allows transformers to consider words from thousands of tokens away.
4. Inference: Generating Text
Once the model is trained, it can be used for inference—the process of generating text based on user input.
How Does ChatGPT Generate Responses?
- Tokenize the input (convert words into numbers).
- Feed the input into the trained model to get a probability distribution of possible next tokens.
- Sample the next token based on probabilities.
- Repeat until a stopping condition is met (e.g., reaching max token length).
Example: Generating Text Step-by-Step
Input:
👉 "Tell me about the moon."
Step 1: Tokenize → [1004, 302, 88, 200, 999]
Step 2: Predict next token probabilities →
"is"(70%)"was"(20%)"has"(5%)
Step 3: Choose "is" (randomness can be adjusted via temperature).
Step 4: Repeat for the next word.
Why Does ChatGPT Give Different Answers?
- Temperature = 0: Always picks the most likely word (deterministic output).
- Temperature = 1: Introduces randomness, making responses more creative.
5. Computational Power: Why AI Models Require GPUs
Training LLMs requires massive computational resources.
- Training GPT-4 took thousands of NVIDIA H100 GPUs, running for weeks.
- Cost estimate: Training a state-of-the-art LLM costs millions of dollars.
Why Do We Need So Many GPUs?
- LLMs rely on matrix multiplications (which GPUs are optimized for).
- A single forward pass through a large model requires trillions of floating-point operations.
- The larger the model, the more GPUs needed to process it efficiently.
💡 NVIDIA’s dominance in AI hardware has made it one of the most valuable companies in the world.
Conclusion: The Power and Limitations of LLMs
What We Learned
- LLMs are trained on vast internet datasets, heavily filtered for quality.
- Text is tokenized into numerical data to be processed by neural networks.
- Transformers allow efficient parallel processing and long-range context handling.
- Inference works by predicting the most likely next token in a sequence.
- Training these models requires enormous computational resources.
Limitations of LLMs
- Hallucinations: LLMs don’t truly “know” facts; they generate the most likely text.
- Bias: If training data is biased, model outputs will reflect that bias.
- Token limitations: Context length restrictions can limit the quality of responses.
🚀 Final Thought: Despite their flaws, LLMs represent one of the most exciting advancements in AI. Understanding how they work helps us use them more effectively and responsibly.
About the video author Andrej Karpathy
Andrej Karpathy is a Slovak-Canadian computer scientist renowned for his contributions to artificial intelligence, particularly in deep learning and computer vision. Born on October 23, 1986, in Bratislava, Czechoslovakia (now Slovakia), he moved to Toronto, Canada, at the age of 15. He earned bachelor’s degrees in Computer Science and Physics from the University of Toronto in 2009, followed by a master’s degree from the University of British Columbia in 2011, where he researched physically-simulated figures.
In 2015, Karpathy completed his PhD at Stanford University under the supervision of Fei-Fei Li, focusing on the intersection of natural language processing and computer vision. During his time at Stanford, he co-designed and was the primary instructor for CS231n: Convolutional Neural Networks for Visual Recognition, the university’s first deep learning course, which grew significantly in popularity.
Karpathy was a founding member of OpenAI, serving as a research scientist from 2015 to 2017. He then joined Tesla in June 2017 as the Director of Artificial Intelligence, leading the Autopilot Vision team responsible for developing advanced driver assistance systems. After a sabbatical, he announced his departure from Tesla in July 2022.
In 2023, Karpathy returned to OpenAI to work on improving GPT-4. By July 2024, he founded Eureka Labs, an AI-integrated education platform aiming to enhance digital learning through AI-driven teaching assistants. Eureka Labs’ inaugural course, LLM101n, is an undergraduate-level class designed to help students train their own AI models.
Throughout his career, Karpathy has been dedicated to education, sharing his expertise through online tutorials and lectures, making complex AI concepts accessible to a broad audience.