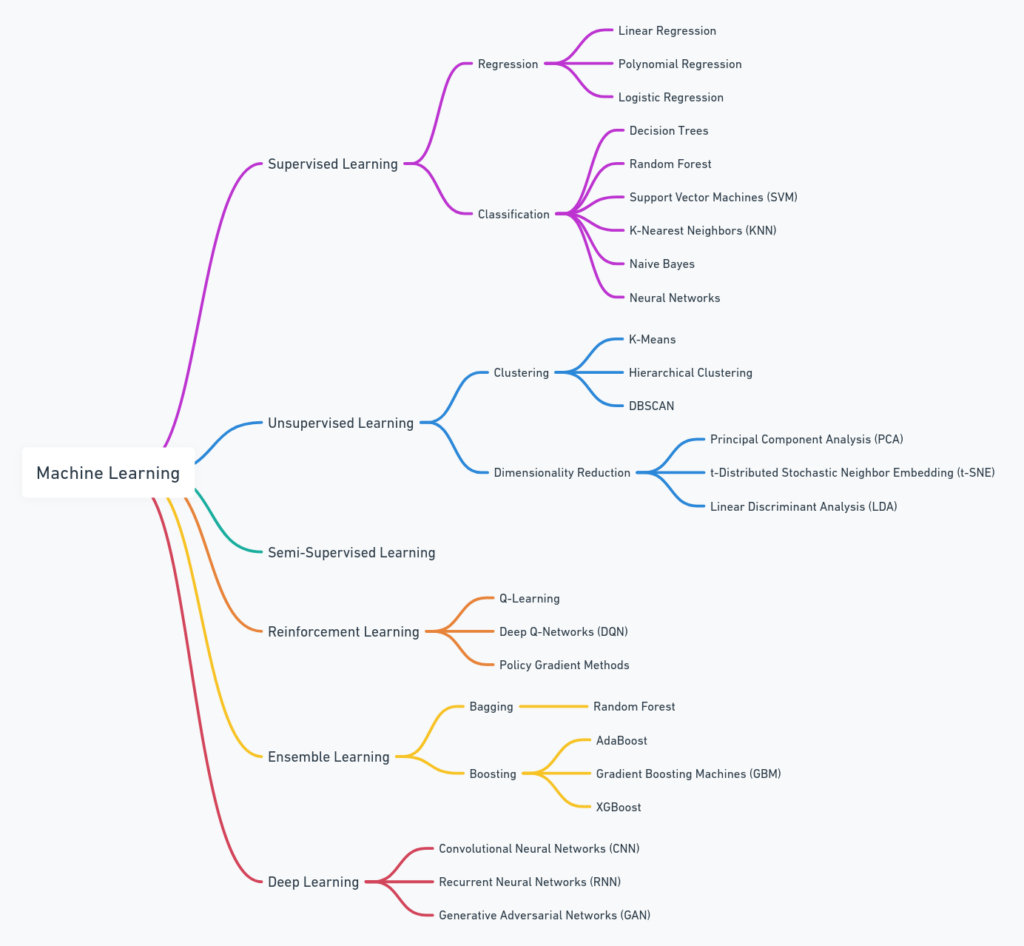
Machine learning is a vast and exciting field that has seen rapid growth in recent years. As a beginner, it can be overwhelming to figure out where to start and how to structure your learning path. To help you get started, we have created a mind map that outlines the major machine learning algorithms and techniques. This guide will walk you through the mind map and provide a step-by-step plan to study machine learning effectively.
Understanding Machine Learning
Before diving into the specifics, it’s important to understand what machine learning is. Machine learning is a subset of artificial intelligence (AI) that involves training algorithms to make predictions or decisions based on data. It can be broadly categorized into several types:
- Supervised Learning
- Unsupervised Learning
- Semi-Supervised Learning
- Reinforcement Learning
- Ensemble Learning
- Deep Learning
Learning Path
1. Prerequisite Knowledge
Before starting with machine learning, it is essential to have a solid foundation in the following areas:
- Mathematics: Linear algebra, calculus, probability, and statistics.
- Programming: Proficiency in a programming language like Python.
- Data Handling: Basic understanding of data manipulation using libraries like NumPy and pandas.
2. Supervised Learning
Supervised learning involves training a model on labeled data. It is divided into two main types: regression and classification.
Regression: Used for predicting continuous values.
- Linear Regression: Understand the relationship between variables.
- Example: Predicting house prices based on features like size, location, etc.
- Resources: Coursera’s “Supervised Machine Learning: Regression and Classification” by Andrew Ng.
- Polynomial Regression: Capture non-linear relationships.
- Example: Predicting the progression of diseases over time.
- Logistic Regression: Useful for binary classification tasks.
- Example: Predicting whether an email is spam or not.
Classification: Used for predicting discrete categories.
- Decision Trees: Simple and intuitive models that split data into branches.
- Example: Classifying whether a loan applicant is a good or bad credit risk.
- Random Forest: Ensemble method combining multiple decision trees for better accuracy.
- Example: Predicting stock market movements.
- Support Vector Machines (SVM): Effective for high-dimensional spaces.
- Example: Image recognition tasks.
- K-Nearest Neighbors (KNN): Classifies based on the closest data points.
- Example: Recommending products based on customer behavior.
- Naive Bayes: Based on Bayes’ theorem, good for text classification.
- Example: Sentiment analysis of customer reviews.
- Neural Networks: The foundation of deep learning, useful for complex patterns.
- Example: Handwritten digit recognition.
3. Unsupervised Learning
Unsupervised learning deals with unlabeled data and is used to find hidden patterns or intrinsic structures in data.
Clustering: Grouping data points based on similarity.
- K-Means: Partitions data into k clusters.
- Example: Customer segmentation for marketing.
- Hierarchical Clustering: Builds a hierarchy of clusters.
- Example: Organizing news articles into categories.
- DBSCAN: Identifies clusters of varying shapes and sizes.
- Example: Identifying outliers in network traffic data.
Dimensionality Reduction: Reducing the number of features in a dataset.
- Principal Component Analysis (PCA): Projects data to a lower-dimensional space.
- Example: Reducing the number of variables in genomics data.
- t-Distributed Stochastic Neighbor Embedding (t-SNE): For visualizing high-dimensional data.
- Example: Visualizing complex datasets like word embeddings.
- Linear Discriminant Analysis (LDA): Finds the linear combinations that best separate classes.
- Example: Pattern recognition in facial images.
4. Semi-Supervised Learning
Semi-supervised learning uses both labeled and unlabeled data to improve learning accuracy. This approach is particularly useful when labeled data is scarce and expensive to obtain.
- Example: Classifying medical images where labeled data is limited but unlabeled data is abundant.
5. Reinforcement Learning
Reinforcement learning is about training agents to make a sequence of decisions by rewarding them for correct actions.
- Q-Learning: A simple algorithm for finding the optimal policy.
- Example: Navigating a maze.
- Deep Q-Networks (DQN): Combines Q-Learning with deep neural networks.
- Example: Playing video games at a superhuman level.
- Policy Gradient Methods: Directly optimize the policy that an agent uses.
- Example: Autonomous driving.
6. Ensemble Learning
Ensemble learning methods combine multiple models to improve performance.
- Bagging: Reduces variance by averaging predictions.
- Random Forest: An ensemble of decision trees.
- Example: Predicting patient outcomes based on medical history.
- Random Forest: An ensemble of decision trees.
- Boosting: Reduces bias by combining weak learners.
- AdaBoost: Adjusts weights based on the errors of previous models.
- Example: Improving the accuracy of binary classification tasks.
- Gradient Boosting Machines (GBM): Builds models sequentially to correct errors.
- Example: Ranking of search engine results.
- XGBoost: An optimized version of GBM.
- Example: Winning Kaggle competitions due to its high performance.
- AdaBoost: Adjusts weights based on the errors of previous models.
7. Deep Learning
Deep learning involves neural networks with many layers (deep neural networks).
- Convolutional Neural Networks (CNN): Excellent for image processing tasks.
- Example: Image classification tasks like identifying objects in photos.
- Recurrent Neural Networks (RNN): Ideal for sequential data like time series or text.
- Example: Language translation and sentiment analysis.
- Generative Adversarial Networks (GAN): Consist of two networks (generator and discriminator) that compete to create realistic data.
- Example: Generating realistic images or deepfakes.
Suggested Order to Learn Algorithms
- Start with the Basics: Learn the prerequisite knowledge in mathematics, programming, and data handling.
- Supervised Learning: Begin with regression techniques, then move to classification methods.
- Unsupervised Learning: Explore clustering and dimensionality reduction techniques.
- Semi-Supervised Learning: Understand how to leverage both labeled and unlabeled data.
- Reinforcement Learning: Study basic reinforcement learning concepts and algorithms.
- Ensemble Learning: Learn about bagging and boosting techniques.
- Deep Learning: Once comfortable with the basics, dive into deep learning, starting with neural networks and progressing to CNNs, RNNs, and GANs.
Resources
- Books:
- “Introduction to Machine Learning with Python” by Andreas C. Müller
- “Deep Learning” by Ian Goodfellow
- Online Courses:
- Coursera’s Machine Learning by Andrew Ng
- Fast.ai’s Practical Deep Learning for Coders
- Practice:
- Kaggle competitions
- Real-world projects
- Online coding platforms
Conclusion
By following this structured path and utilizing the mind map, you can navigate the vast field of machine learning with confidence. Remember, the key to mastering machine learning is practice and continuous learning. Good luck on your journey!