
This is my reading notes for Chapter 7 in book “System Design Interview – An insider’s guide (Vol. 1)”.
Table of Contents
Overview
Chapter 7 of “System Design Interview: An Insider’s Guide” tackles the challenge of generating unique IDs across distributed systems. The central problem arises from the need to ensure that each generated ID is unique, sortable by time, and fits within a fixed-length structure (typically 64 bits). In distributed systems, where multiple servers or services generate IDs independently, the difficulty is in coordinating the generation process without centralized bottlenecks or synchronization issues.
Key Points and Concepts
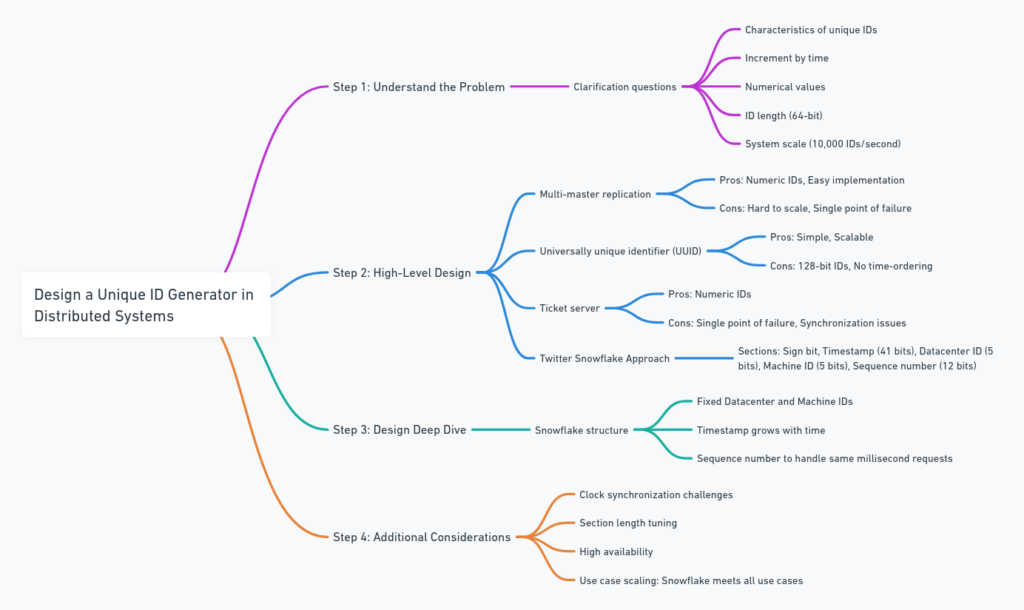
- Understanding the Problem
In distributed systems, generating unique IDs is crucial for a wide variety of applications. Unique IDs serve as primary keys in databases, identifiers for transactions, messages, logs, and more. Traditionally, databases use auto_increment fields to generate unique IDs. However, this approach fails in distributed environments due to the challenges of coordination and scalability.
- System Requirements
When designing a unique ID generator, the following requirements must be addressed:
- Uniqueness: Each ID must be globally unique across different servers and instances.
- Numerical Representation: IDs must be numerical and fit within a predefined bit-length (typically 64 bits).
- Time-Sortable: IDs should be ordered based on the time of their generation.
- High Throughput: The system must support generating tens of thousands of IDs per second without conflicts or delays.
- Scalability: The solution must scale horizontally as the number of machines and services grows.
Additional constraints include fault tolerance, high availability, and minimal latency during ID generation.
- Common Approaches to Unique ID Generation
Several methods are explored in the chapter, each with its pros and cons:
- Multi-master Auto-Increment: The approach involves using traditional auto_increment on multiple database instances, with an increment step of k (the number of servers). For example, if k = 3, server 1 generates IDs as 1, 4, 7…, server 2 generates 2, 5, 8…, and so on. While simple, this approach struggles with scaling and maintaining synchronization between servers. Failures can lead to ID duplication or gaps.
- UUID (Universally Unique Identifier): UUIDs are 128-bit identifiers that can be generated independently by each machine without requiring coordination. They are unique due to their reliance on factors such as the machine’s MAC address, timestamp, and random numbers. However, UUIDs are not time-sortable and consume more memory (128 bits vs. 64 bits). Additionally, their randomness makes them inefficient for indexing and querying in databases, leading to performance bottlenecks.
- Ticket Server: In this centralized approach, a dedicated server generates IDs and distributes them to clients upon request. The ticket server maintains an auto-increment counter. While this method guarantees uniqueness, it introduces a single point of failure and can become a bottleneck, especially in high-traffic systems.
- Twitter Snowflake Algorithm
The Snowflake algorithm, developed by Twitter, offers a highly efficient solution for distributed ID generation. It ensures uniqueness, time-sorting, and scalability while fitting within a 64-bit structure. This approach is often recommended due to its simplicity and ability to scale effectively.
Snowflake ID Structure (64 bits):
- 1 bit (Unused/Sign Bit): Reserved for future use and always set to 0. This bit ensures the generated ID is positive.
- 41 bits (Timestamp): Represents the number of milliseconds since a custom epoch. This field allows IDs to be sorted by time and provides sufficient capacity to last for approximately 69 years.
- 5 bits (Datacenter ID): Identifies the data center where the ID was generated. This allows for 32 different data centers to be uniquely identified.
- 5 bits (Machine ID): Identifies the machine within the data center generating the ID. This supports 32 machines per data center.
- 12 bits (Sequence Number): Represents the count of IDs generated within the same millisecond on a single machine. With 12 bits, up to 4,096 unique IDs can be generated per millisecond on each machine.
Example: Imagine we are generating IDs using the Snowflake algorithm. Let’s assume:
- Timestamp: The current timestamp is 1627760000000 milliseconds since the epoch.
- Datacenter ID: This is set to 1.
- Machine ID: This is set to 5.
- Sequence Number: The sequence number starts at 0 and increments for each subsequent ID within the same millisecond.
The first ID might look like this:
000000001101111011111111111110000011000100000000000000000000000When broken down:
- Timestamp: 1627760000000 in binary (41 bits).
- Datacenter ID: 1 (5 bits).
- Machine ID: 5 (5 bits).
- Sequence Number: 0 (12 bits).
The next ID generated within the same millisecond will simply increment the sequence number.
- Handling Failure Scenarios
Snowflake’s distributed ID generation model is not without challenges:
- Clock Drift: One of the biggest risks is that clocks across machines might drift, leading to time mismatches. If a machine’s clock moves backward, it could generate conflicting IDs. To mitigate this, the system needs clock synchronization using protocols like NTP (Network Time Protocol).
- Exhausting Sequence Numbers: If a machine generates more than 4,096 IDs within the same millisecond, the system must either wait until the next millisecond or scale horizontally by adding more machines.
- Datacenter Failures: If a datacenter or machine fails, replication and failover mechanisms need to be in place. Machines in the same datacenter should be able to take over ID generation with the same datacenter ID but different machine IDs.
- Alternative Solutions
Depending on the use case, the chapter also suggests other solutions that can be considered:
- Zookeeper-based ID Generation: Zookeeper can be used to coordinate distributed ID generation by maintaining a global counter. This method guarantees uniqueness but introduces latency due to the overhead of coordination.
- Database-backed ID Generation: Some systems opt to generate IDs using database transactions. For example, the database can maintain a global_sequence table and each server can reserve a batch of IDs. However, this method may introduce contention as multiple servers compete for ID ranges.
- Trade-offs and Performance Considerations
In any system design, trade-offs must be carefully evaluated. The chapter highlights:
- Consistency vs. Availability: Centralized solutions like ticket servers or database-backed ID generation prioritize consistency but suffer from availability issues (e.g., single points of failure). In contrast, distributed approaches like Snowflake enhance availability at the cost of increased complexity in ensuring time synchronization.
- Performance: Systems generating a high volume of IDs per second must focus on minimizing latency. The Snowflake approach, being distributed, ensures high throughput with low latency.
- Tuning the Snowflake Algorithm
Depending on the specific requirements of a system, the different sections of the 64-bit ID can be tuned:
- Short-lived Systems: In systems expected to run for less than a few years, fewer bits can be allocated to the timestamp field, freeing up space for larger sequence numbers or machine IDs.
- High Throughput Systems: Systems with a very high ID generation rate may need to increase the sequence number field to handle more IDs per millisecond. However, this may reduce the timestamp field and the effective lifetime of the system.
Example: Suppose you are building a high-frequency trading platform that generates millions of IDs per second. You may decide to allocate 14 bits to the sequence number, allowing up to 16,384 IDs per millisecond. In this case, you would reduce the timestamp field to 39 bits, which still provides several decades of uptime.
The key takeaway from this chapter is the importance of balancing system performance, scalability, and reliability when designing a distributed unique ID generator. The Snowflake algorithm offers an elegant solution that meets most modern system requirements, but it still requires careful implementation, particularly around clock synchronization and handling failure scenarios.
Insights and Reflections
This chapter also reinforces the need to always think about trade-offs in system design. While UUIDs are straightforward and require no coordination, they sacrifice performance and sorting. Conversely, centralized ticket servers simplify ID generation logic but create bottlenecks and single points of failure. The right solution depends on the specific use case, traffic patterns, and system architecture.
Further Learning
- NTP and Clock Synchronization: Understanding the technical details of clock synchronization and how drift can impact distributed systems.
- Resilience in Distributed Systems: Exploring techniques like consensus algorithms (e.g., Paxos, Raft) that ensure distributed systems remain consistent and available under failure conditions.
- Distributed Databases: Investigating how distributed databases handle unique key generation and coordination, such as using Paxos-based counters or leader-based approaches.
This chapter is highly applicable for system designers who need to implement scalable and reliable solutions in real-world distributed environments, especially when high-throughput and low-latency ID generation is crucial.