This is my reading notes for Chapter 9 in book “System Design Interview – An insider’s guide (Vol. 1)”.
Introduction
Chapter 9 of System Design Interview: An Insider’s Guide by Alex Xu dives into the complexities of designing a scalable and efficient web crawler. A web crawler, also known as a spider or robot, is crucial for tasks like search engine indexing, web archiving, and monitoring online content. The chapter breaks down the design into steps and offers insights into the challenges and solutions necessary to create a crawler capable of handling large-scale operations.
Key Concepts
- Problem Understanding The basic algorithm for a web crawler can be summarized in three core steps:
- Download a set of URLs.
- Extract new URLs from the downloaded content.
- Repeat the process for the new URLs.
- Questions to ask:
- What kind of pages will the crawler process? Will it handle static HTML or dynamic content such as JavaScript-generated pages?
- What should be the frequency of revisiting pages?
- Will the crawler handle different content types like images, PDFs, or videos?
- How should the system manage duplicate content and pages that frequently change?
- Example: A crawler designed for a search engine might be required to handle millions of pages per day, whereas one created for monitoring updates on a smaller website might only need to check a few hundred pages.
- Design Principles:
- Scalability: The system must scale horizontally to handle billions of pages. Distributed processing is key to handling this level of data.
- Politeness: The crawler should respect the limitations of the websites it crawls. This includes not sending too many requests too quickly to a single domain to avoid overloading servers.
- Extensibility: The design should support the easy addition of new content types (e.g., images, PDFs, multimedia) and be adaptable to different parsing requirements.
- Robustness: The crawler needs to be resilient to network failures, invalid HTML, spider traps (pages that automatically generate new links), and unexpected content. It should be able to recover from crashes without losing its state.
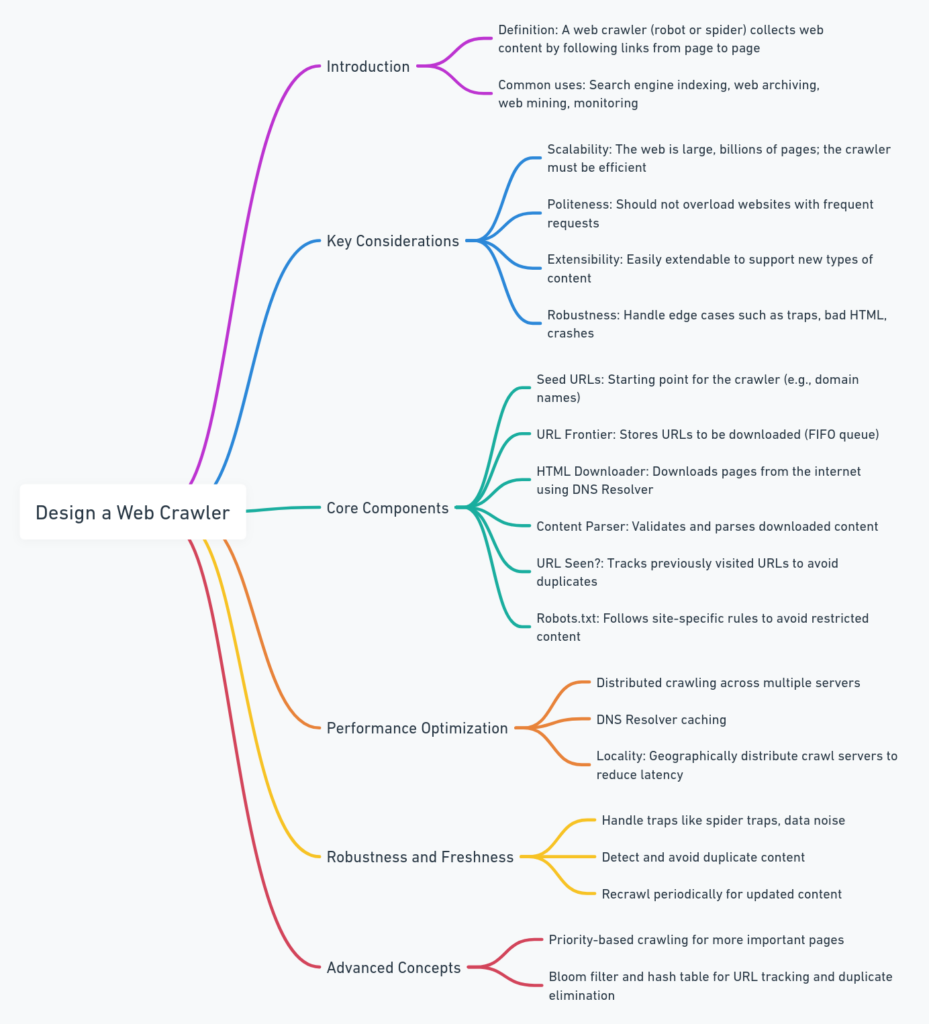
Design Components
- Seed URLs
- The starting point for a crawler is a list of seed URLs, which serve as entry points into the web. These seeds could represent key areas of interest, such as popular websites, topic-focused pages, or localized domains.
- Example: For a news crawler, seed URLs might include the homepages of major news outlets. For an e-commerce crawler, the seeds could be the landing pages of popular e-commerce sites.
- URL Frontier
- The URL Frontier is a data structure (typically a queue) that holds URLs yet to be processed. It is critical for controlling the order in which URLs are crawled, as well as ensuring politeness by spacing requests to the same domain.
- Politeness Mechanism: The system can throttle requests to the same domain by scheduling them at specific intervals. A priority queue could be used to prioritize popular or frequently updated pages.
- Example: Googlebot, the Google search engine crawler, uses a sophisticated URL frontier that prioritizes high-traffic websites to ensure that critical content is indexed faster.
- HTML Downloader
- The HTML Downloader is responsible for retrieving the raw content of the web page. It handles HTTP requests, follows redirects, and interacts with a DNS resolver to convert domain names into IP addresses.
- Optimizations: Techniques like DNS caching can minimize lookup times, while retry logic ensures robustness when servers are temporarily unavailable.
- Example: Distributed crawlers often run multiple downloaders in parallel, each assigned to a specific subset of URLs. These downloaders run across geographically dispersed servers to reduce latency and improve download speeds.
- Content Parser
- The Content Parser extracts data from the downloaded HTML pages. It identifies and follows hyperlinks, extracting new URLs to add to the URL Frontier. It also checks if the page contains relevant content and filters out unnecessary parts, such as advertisements.
- Dealing with Duplicates: The system hashes the content of each page to detect duplicates. This prevents the crawler from processing the same page multiple times.
- Example: A crawler parsing news articles might look for <article> tags in HTML to extract the article text while ignoring sidebars, comments, and advertisements.
- Robustness
- The crawler must handle a variety of failure modes: unresponsive websites, malformed HTML, spider traps, and network issues. A robust crawler saves its state to disk, allowing it to resume where it left off in the event of a crash.
- Example: Implementing a checkpointing system allows the crawler to save its progress at regular intervals. If a crash occurs, the system can reload the last saved state instead of starting over.
- Politeness and Prioritization
- Politeness: To avoid overloading websites, the crawler sends requests at a controlled rate to each domain. This can be enforced through a delay mechanism in the URL Frontier, ensuring that only a certain number of requests are sent to a given domain within a time window.
- Prioritization: URLs can be prioritized based on their importance. For example, pages with high PageRank, frequently updated pages, or pages critical for SEO can be given higher priority in the crawling schedule.
- Example: The crawler might prioritize crawling homepages and category pages of e-commerce websites before diving into individual product pages.
- Avoiding Problematic Content
- The crawler needs to avoid problematic URLs such as spider traps—pages with an infinite number of links generated dynamically. Limits on URL depth and length can be set to prevent the crawler from getting stuck.
- Example: A crawler should avoid URLs that are very deep (e.g., /category/product/subcategory/item123456789) to avoid unnecessary processing of low-value pages.
Performance and Extensibility
- Distributed Crawling
- A scalable web crawler uses distributed crawling across multiple servers to process URLs in parallel. This reduces latency and improves the speed at which large amounts of data are processed.
- Example: The Nutch project is an open-source distributed web crawler built on top of Apache Hadoop that scales across a cluster of machines to crawl large portions of the web.
- Data Storage and Management
- Efficient data management ensures that crawled content is stored and processed correctly. The system uses a mix of in-memory storage for frequently accessed data and disk storage for long-term archiving.
- Example: For frequently changing content like news websites, the crawler can store the HTML of the pages in memory for quick access and use databases or cloud storage (e.g., Amazon S3) for archived data.
- Cache Optimization
- Cached content and DNS responses can significantly reduce the overhead on the system. Caching the content of frequently visited pages prevents unnecessary re-downloading and reprocessing.
- Example: A search engine crawler like Bing uses a caching layer to store popular pages for quick retrieval, reducing the need to hit the same website multiple times.
Examples
- Googlebot: This is one of the most well-known web crawlers, used by Google to index websites for its search engine. Googlebot prioritizes websites based on importance and popularity and uses a highly distributed architecture to crawl billions of web pages.
- Common Crawl: An open-source initiative that provides a freely available dataset of web data collected by a distributed web crawler. The crawler gathers petabytes of data from across the web, which is then used for research and analytics.
- Website Monitoring Crawlers: Companies use crawlers to monitor their websites for changes, broken links, and outages. These crawlers often focus on a specific set of URLs and do not require the massive scale of search engine crawlers.
Conclusion
Designing a web crawler involves balancing multiple factors such as performance, scalability, and politeness. By carefully managing the components of the system—such as the URL Frontier, HTML Downloader, and Content Parser—a web crawler can efficiently process large amounts of data. Extensibility and robustness ensure that the system can evolve and continue functioning in the face of new challenges, such as handling new content types or responding to network failures.
This chapter provides a detailed framework for building a robust and scalable web crawler, offering solutions to common issues like politeness, handling duplicate content, and optimizing performance through distributed systems and caching
I¦ve recently started a website, the information you offer on this site has helped me tremendously. Thanks for all of your time & work.