This is my reading notes for Chapter 5 in book “System Design Interview – An insider’s guide (Vol. 1)”.
Table of Contents
Introduction to Consistent Hashing
Consistent hashing is a crucial technique for managing distributed systems, especially when the number of servers (nodes) can change dynamically. It ensures minimal disruption and data redistribution when servers are added or removed, making it an essential tool for maintaining scalability and efficiency in distributed architectures.
The Rehashing Problem with Traditional Hashing
- Traditional Hashing Mechanism: In traditional hashing, the hash function distributes keys across
Nservers. A common approach is:serverIndex = hash(key) % NThis method works effectively whenN(the number of servers) is fixed. - Problem of Rehashing: When the number of servers changes (e.g., a server is added or removed), the modulo operation’s result changes for most keys, leading to massive reallocation of keys across servers. This results in:
- Cache Misses: Because most keys are reallocated, the system experiences many cache misses, reducing performance.
- Data Movement: Significant amounts of data need to be moved to rebalance the load, which is computationally expensive and time-consuming.
Example:
- Suppose there are 4 servers, and the hash function distributes keys evenly among them using
hash(key) % 4. - If one server is removed, reducing the number to 3 (
hash(key) % 3), the keys originally hashed to the fourth server must be redistributed, leading to a large-scale reshuffling of data.
Consistent Hashing: The Solution
Consistent hashing addresses the rehashing problem by introducing a more flexible and efficient method for distributing keys.
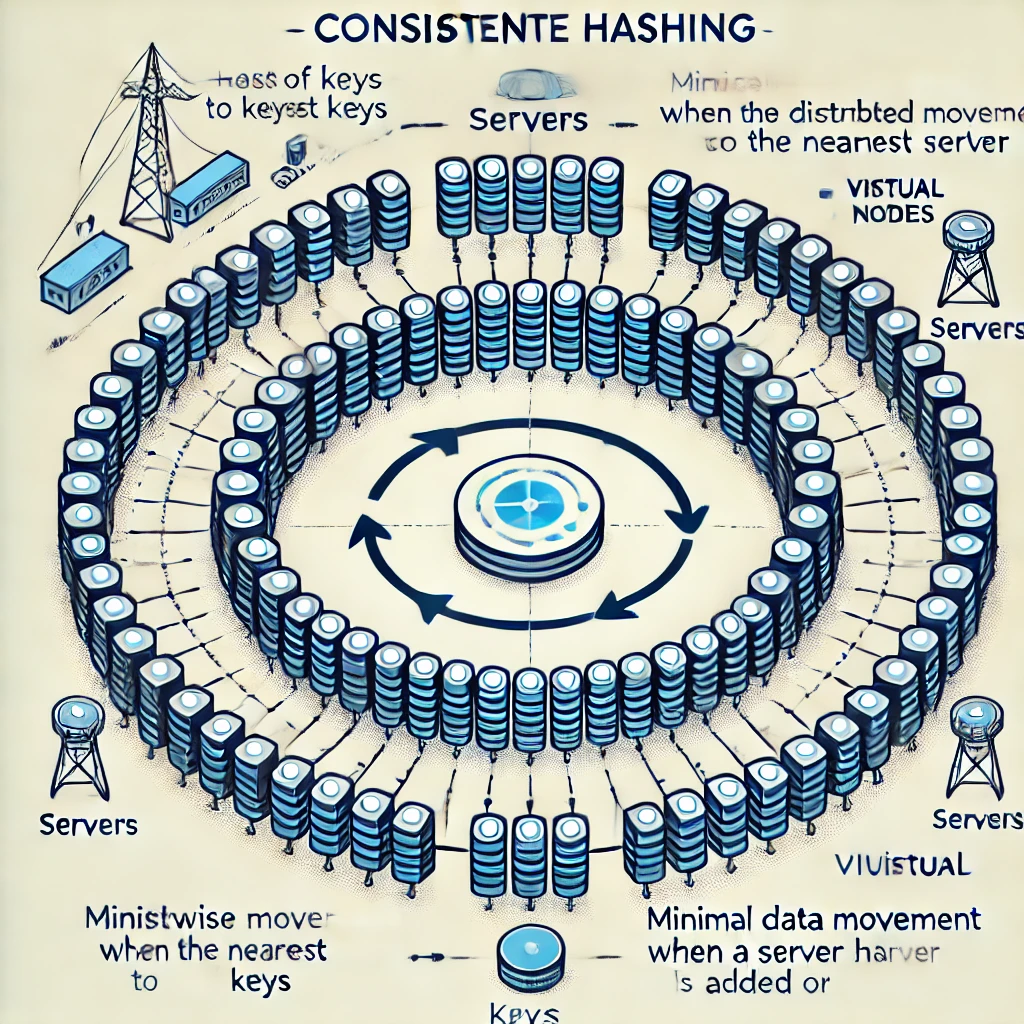
- Hash Ring Concept: Instead of mapping keys directly to servers using modulo arithmetic, consistent hashing maps both servers and keys to a circular hash space (0 to
2^160 - 1).- Server Placement: Each server is assigned a point on this ring using the same hash function.
- Key Placement: Keys are also hashed to a point on the ring.
- Key Lookup: To find the appropriate server for a key, the system moves clockwise on the ring from the key’s hash value until it finds the nearest server. This server is responsible for that key.
- Minimal Data Movement: When a server is added or removed:
- Only a small fraction of keys need to be reassigned.
- Most keys remain on the same server, drastically reducing the amount of data that needs to be moved.
Challenges in Basic Consistent Hashing
While consistent hashing solves the rehashing problem, it introduces new challenges:
- Uneven Distribution: If servers are not evenly distributed on the ring, some servers might handle more keys than others, leading to load imbalance.
- Hotspots: A server that handles too many keys may become a hotspot, experiencing higher load and potential performance degradation.
Virtual Nodes: Enhancing Consistent Hashing
To mitigate the uneven distribution and hotspots, consistent hashing introduces the concept of virtual nodes (or replicas).
- Virtual Nodes Explained:
- Multiple Positions: Each physical server is represented by multiple virtual nodes on the hash ring.
- Balanced Distribution: By having multiple points on the ring, the load is more evenly distributed across servers, reducing the likelihood of hotspots.
How Virtual Nodes Work:
- Load Balancing: By assigning multiple virtual nodes to each server, the keys are distributed more evenly across the servers.
- Flexibility: The number of virtual nodes per server can be adjusted based on the server’s capacity. More powerful servers can be assigned more virtual nodes to handle a larger share of the load.
Practical Considerations in Implementing Consistent Hashing
- Choosing the Hash Function: The choice of hash function is critical for consistent hashing. A good hash function ensures an even distribution of keys and minimizes collisions.
- Handling Failures: When a server fails, the keys assigned to its virtual nodes are automatically redistributed to the nearest servers on the hash ring, ensuring minimal disruption.
- Replication for Fault Tolerance: Consistent hashing can be combined with data replication strategies to improve fault tolerance. Each key can be replicated across multiple servers to ensure availability even if one server goes down.
Real-World Applications of Consistent Hashing
Consistent hashing is widely used in various distributed systems to manage data partitioning and load balancing. Some notable applications include:
- Amazon’s DynamoDB: Uses consistent hashing to distribute data across nodes and manage replication for fault tolerance.
- Apache Cassandra: Employs consistent hashing to distribute and replicate data across a distributed database system, ensuring high availability and scalability.
- Discord’s Chat System: Leverages consistent hashing to manage millions of concurrent users by distributing chat data evenly across multiple servers.
- Akamai CDN: Uses consistent hashing to balance the load across its network of edge servers, ensuring efficient content delivery worldwide.
- Maglev Network Load Balancer: Google’s Maglev employs consistent hashing for load balancing to distribute incoming requests evenly across backend servers.
Detailed Examples
- Adding a New Server:
- Suppose a new server is added to the system. In traditional hashing, this would require rehashing most keys. However, with consistent hashing, only the keys that would fall between the new server’s position and the next server on the hash ring need to be moved. This minimizes the impact on the system.
- Removing a Server:
- When a server is removed, consistent hashing ensures that only the keys assigned to the removed server’s position need to be reassigned to the next server on the ring. This again results in minimal disruption and efficient rebalancing.
Conclusion
Consistent hashing is a powerful technique for managing distributed systems, particularly in environments where the number of servers can change dynamically. It ensures efficient load balancing, minimal data movement during scaling operations, and robust handling of server failures. By understanding and implementing consistent hashing, system designers can create scalable, resilient distributed systems capable of handling large volumes of data and traffic.