This is my reading notes for Chapter 15 in book “System Design Interview – An insider’s guide (Vol. 1)”.
Google Drive is a cloud storage and file synchronization service that enables users to upload, store, and share files across devices and access them from anywhere. The design focuses on building a system that can efficiently handle large-scale storage, fast file synchronization, file sharing, and version control. Below is a comprehensive breakdown of how to approach designing such a system.
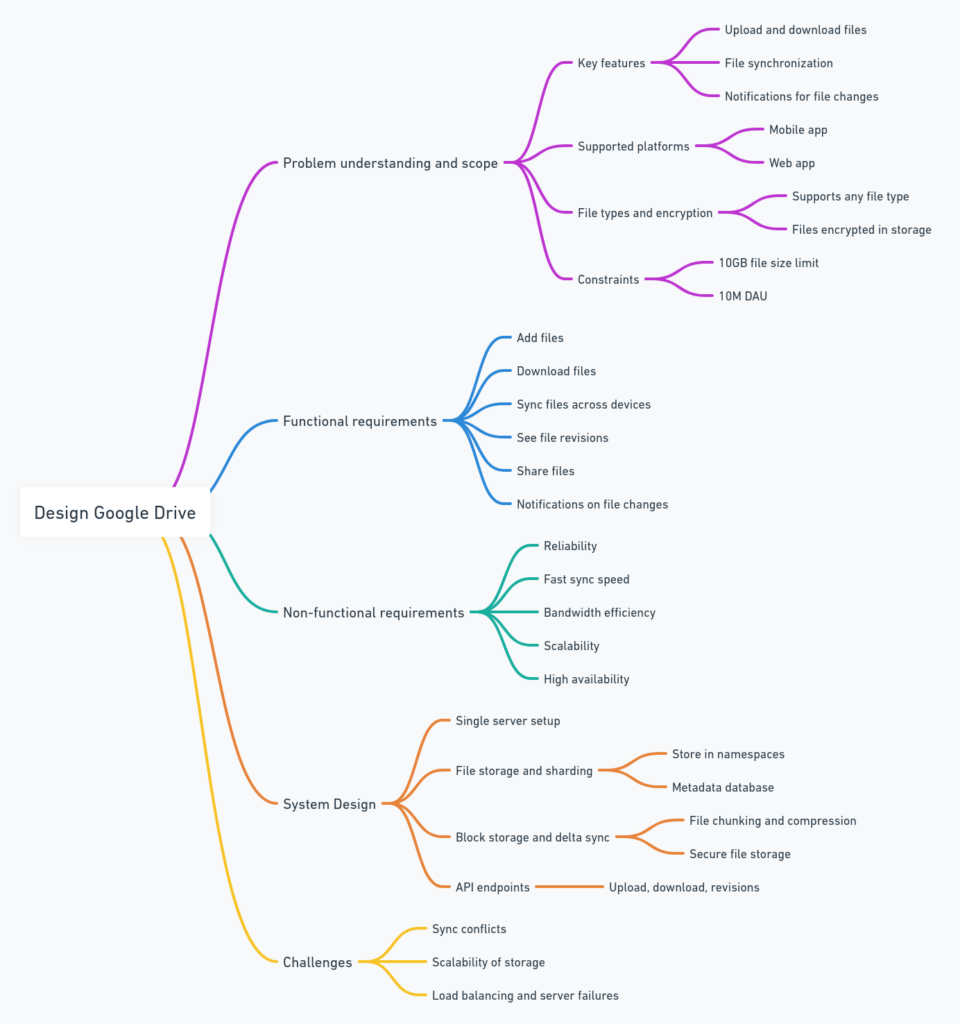
1. Understanding the Problem and Requirements
Key Functional Features:
- Upload and download files:
- Users can upload various file types and download them later.
- Examples: Uploading a 100 MB video file, downloading a 2 MB PDF from Google Drive.
- File synchronization:
- Files need to be synchronized across all devices (laptops, mobile, tablets) as soon as there’s a change.
- Example: A user edits a file on their laptop, and the changes automatically appear on their mobile phone within seconds.
- File sharing:
- Users can share files or folders with others and assign different permissions (e.g., view-only, edit).
- Example: Sharing a Google Docs file with colleagues, allowing them to comment but not edit.
- File versioning:
- Keeping track of changes made to files and allowing users to access previous versions.
- Example: Recovering an older version of a spreadsheet from two weeks ago.
Non-functional Requirements:
- High reliability and durability:
- Data must be available and protected from loss, even during failures. A 99.999999999% durability is expected for file storage.
- Example: If a server in one region fails, data is still available due to replication across other regions.
- Fast synchronization and low latency:
- Syncing should be nearly real-time for small files and changes.
- Example: A change made on a text document should reflect on another device in less than a second.
- Scalability:
- The system must scale to handle millions of users and petabytes of data.
- Example: Google Drive has over 1 billion users and needs to handle high concurrency and traffic spikes.
- Cost-efficiency:
- The design should minimize costs related to bandwidth, storage, and CPU processing.
2. Back-of-the-Envelope Estimations
To understand the scale of the system:
- User base: Assume there are 50 million users, with 10 million daily active users (DAU).
- Storage needs: Each user gets 10 GB of free storage.
- Total storage requirement: 50million×10GB=500Petabytes
- Example: Handling this much data requires robust storage solutions like Amazon S3, which can scale to petabyte levels.
- File upload traffic: Assume each file is 500 KB on average, and 10 million DAU upload 3 files daily.
- Daily uploads: 10million×3×500KB=15TB/day
- QPS (Queries per second): To estimate peak QPS:
- During peak hours, if 5% of users upload files simultaneously:
- 10 million / (3600 X 2) ≈700QPS
- During peak hours, if 5% of users upload files simultaneously:
3. Proposed High-Level Design
Google Drive requires a distributed, scalable architecture to handle millions of users and high traffic volumes. The design can be broken down into several core components:
File Storage and Metadata Separation:
- Files and metadata should be stored separately to improve scalability.
- File Storage: Store actual files in cloud storage services like Amazon S3 or Google Cloud Storage, which offer durability and replication.
- Metadata Storage: Store metadata (file name, size, owner, permissions, etc.) in a SQL database (e.g., MySQL) for fast queries. Metadata can be further optimized by using caching.
File Chunking and Block Servers:
- Large files should be divided into blocks or chunks (e.g., 4 MB blocks). Block servers handle breaking files into these smaller chunks.
- Example: When a user uploads a 100 MB video, it is split into 25 chunks (100 MB ÷ 4 MB = 25 chunks). These chunks are stored separately and synced in parallel.
- Advantage: Only modified chunks need to be synced when files are updated, reducing bandwidth usage.
Delta Syncing:
- For small file changes, delta syncing is used, meaning only the changes (deltas) are transmitted instead of the entire file.
- Example: If a user changes one paragraph in a 50 MB document, only a few kilobytes of data representing that change are synced, rather than the entire 50 MB file.
4. Core Components
- Block Servers:
- Handle the splitting and uploading of files into blocks.
- Example: User uploads a 500 MB video. The block server splits it into 125 chunks (500 MB ÷ 4 MB = 125 chunks) for easier storage and faster parallel uploads.
- Cloud Storage (S3, GCS):
- Stores file chunks. It offers reliability through replication across multiple data centers.
- Example: Each file chunk is stored in three regions, ensuring that even if one region fails, data is still accessible.
- API Servers:
- Manage user requests like uploading, downloading, and sharing files.
- Example: When a user requests to share a file, the API server processes the request and updates the metadata with the sharing permissions.
- Metadata Storage and Caching:
- Metadata, such as file paths, ownership, and permissions, is stored in a SQL database and cached for faster access.
- Example: When retrieving a file, the system first queries the metadata to understand where the file is stored, what permissions are available, etc.
- Notification Service:
- Ensures clients are notified when files are updated, shared, or deleted. This can be done using long polling, WebSocket, or push notifications.
- Example: User A uploads a new version of a document. User B, who has shared access, receives a notification that the file has been updated.
5. Handling Sync Conflicts
- Sync conflicts arise when multiple users edit the same file at the same time. Google Drive needs to handle these conflicts intelligently.
- Example: User A and User B both edit a shared document simultaneously. Google Drive creates two versions of the document and presents both users with an option to either merge the changes or resolve the conflict manually.
6. Data Flow
Upload Flow:
- User uploads a file, which is split into chunks by the block server.
- Each chunk is compressed, encrypted, and sent to cloud storage (e.g., S3 or GCS).
- Once uploaded, the cloud storage sends an acknowledgment, which updates the metadata database and notifies the user of a successful upload.
Download Flow:
- The user requests to download a file, and the metadata server is queried to find the file’s location.
- The file chunks are retrieved from cloud storage and reconstructed into the full file.
- The file is then delivered to the user.
7. Failure Handling and Replication
The system must handle various failure scenarios to ensure high availability:
- Data replication: All file chunks are replicated across multiple regions (e.g., 3 regions) to prevent data loss.
- Example: If the server storing chunks in the US-West region goes offline, users can still access their files from the US-East or Europe regions.
- Notification failure: If a notification server fails, the clients should reconnect to another notification server.
- Metadata database failure: In case the master database fails, a read replica can be promoted to the new master to ensure minimal downtime.
Conclusion:
- Google Drive’s design is a complex distributed system with multiple components handling file storage, syncing, and sharing at scale. Key considerations include optimizing file upload/download times, reducing bandwidth usage through chunking and delta syncing, and ensuring data durability through replication.
- Scalability and reliability are achieved using a cloud-based infrastructure like Amazon S3 or Google Cloud Storage, with APIs handling metadata, notifications, and user interactions.
- Examples like chunking large files, using delta sync for efficient updates, and handling version control demonstrate how these concepts are applied in real-world scenarios.
I’ve been exploring for a little bit for any high quality articles or blog posts in this sort of house . Exploring in Yahoo I ultimately stumbled upon this website. Studying this information So i am happy to convey that I’ve an incredibly excellent uncanny feeling I found out exactly what I needed. I most surely will make certain to do not overlook this web site and provides it a glance on a constant basis.