This is my reading notes for Chapter 1 in book “System Design Interview – An insider’s guide (Vol. 1)”.
Table of Contents
Summary
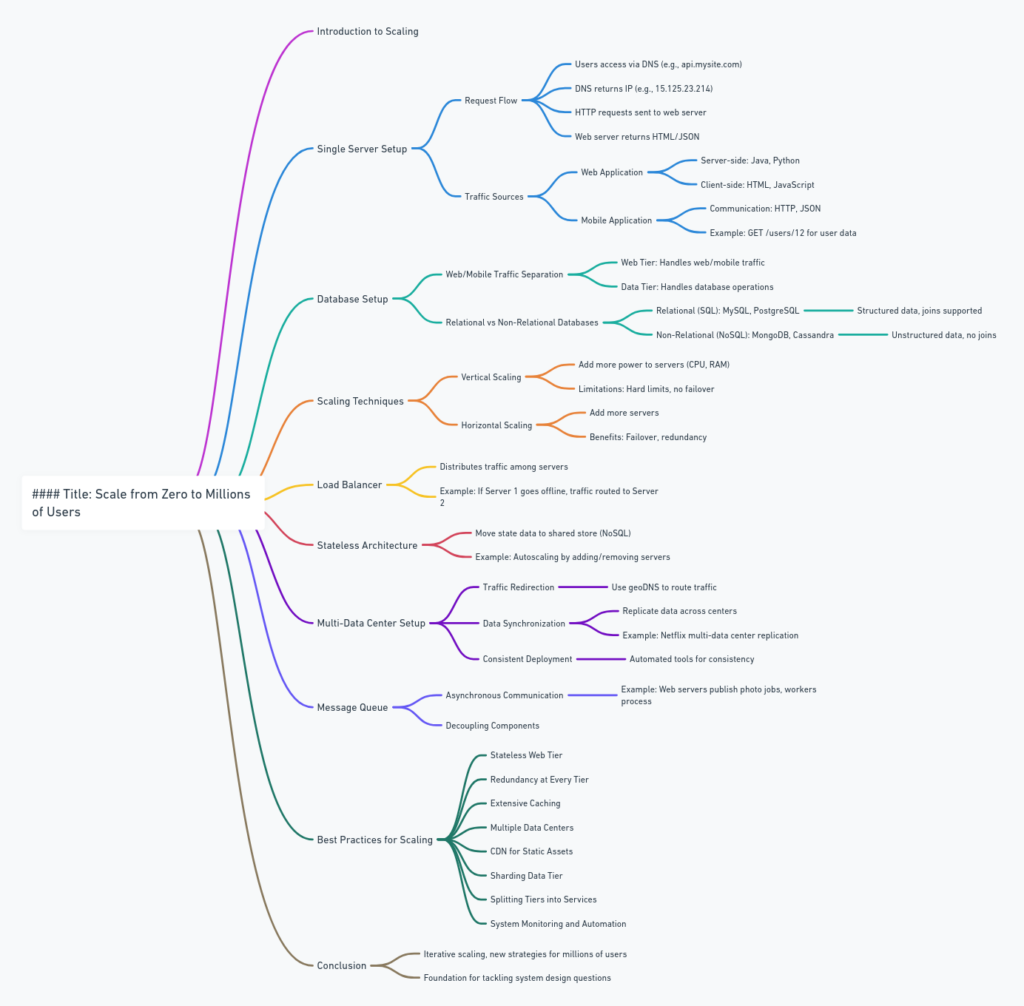
This chapter discusses the journey of designing a system that scales from a single user to millions of users. It emphasizes the importance of continuous refinement and improvement to build a scalable system. Here’s a detailed breakdown of the chapter’s key points:
1. Single Server Setup
- Initial Setup: Start with a single server handling everything—web app, database, cache, etc.
- Request Flow: Users access the site through DNS, which directs traffic to the server via its IP address. The server processes HTTP requests and returns responses.
- Traffic Sources: Traffic comes from both web applications (using server-side and client-side languages) and mobile applications (communicating via HTTP with JSON responses).
2. Database Separation
- Scaling Need: As user base grows, a single server becomes insufficient.
- Separation: Separate the database from the web server for independent scaling. Choose between relational (RDBMS) and non-relational (NoSQL) databases based on application needs.
3. Vertical vs. Horizontal Scaling
- Vertical Scaling: Adding more resources (CPU, RAM) to a single server. Simple but has limits and lacks failover and redundancy.
- Horizontal Scaling: Adding more servers. Preferred for large-scale applications due to better failover and redundancy capabilities.
4. Load Balancer
- Function: Distributes incoming traffic across multiple servers.
- Benefits: Provides failover and improves availability. Can easily add more servers to handle increased traffic.
5. Database Replication
- Master-Slave Model: Master database handles writes, while slave databases handle reads.
- Advantages: Improves performance, reliability, and availability by distributing read operations and providing data redundancy.
6. Caching
- Purpose: Store frequently accessed data in memory to reduce database load and improve performance.
- Cache Tier: Separate cache layer, using in-memory data stores like Memcached or Redis.
- Considerations: Implement expiration policies and strategies to maintain consistency between cache and data store.
7. Content Delivery Network (CDN)
- Static Content: CDN stores and delivers static assets like images, CSS, and JavaScript files to improve load times.
- Dynamic Content: Though not covered in detail, dynamic content caching is mentioned as a newer concept.
8. Stateless Web Tier
- Stateful vs. Stateless: Stateless servers don’t retain user session data, which is stored in a shared data store, allowing any server to handle any request.
- Advantages: Simplifies scaling and improves robustness.
9. Multiple Data Centers
- Geographical Distribution: Use multiple data centers to improve availability and user experience across different regions.
- Challenges: Handle traffic redirection, data synchronization, and consistent testing and deployment across data centers.
10. Message Queue
- Decoupling: Use message queues to decouple components, allowing them to scale independently.
- Use Case: For tasks like photo processing, web servers can publish jobs to a queue, and workers can process them asynchronously.
11. Logging, Metrics, and Automation
- Logging: Essential for identifying errors and monitoring system health.
- Metrics: Collect host-level, aggregated, and key business metrics to gain insights.
- Automation: Automate processes like continuous integration and deployment to improve productivity.
12. Database Scaling
- Vertical Scaling: Limited by hardware constraints and costs.
- Horizontal Scaling (Sharding): Distribute data across multiple servers (shards) using a sharding key. Challenges include data re-sharding and handling hotspot keys.
13. Key Takeaways
- Scalability: Iterative process involving refining and implementing new strategies.
- Core Principles: Keep web tier stateless, build redundancy, cache data, support multiple data centers, use CDN for static assets, shard data, split tiers into services, and monitor the system with automation tools.
Examples from the Chapter
- Single Server Setup:
- User accesses
api.mysite.com, which resolves to IP15.125.23.214. - HTTP requests are sent to the server, which returns HTML or JSON responses.
- User accesses
- Database Replication:
- Master database handles writes, and multiple slave databases handle reads.
- If the master goes offline, a slave is promoted to master to maintain availability.
- Load Balancer:
- Distributes traffic across multiple web servers.
- Ensures that if one server fails, traffic is routed to other servers.
- Caching:
- Web server first checks cache for data. If not found, it queries the database, stores the result in the cache, and returns the data to the client.
- Message Queue:
- Web servers publish photo processing jobs to a queue.
- Photo processing workers pick up jobs from the queue and process them asynchronously.
This chapter provides a comprehensive guide to scaling a system from zero to millions of users, offering practical examples and detailed explanations of each step involved.